Supercharge Your PyTorch Training with Gradient Accumulation
A practical guide to training larger models on limited hardware
Introduction
When training large deep learning models, you often face a fundamental limitation: GPU memory. Larger batch sizes generally lead to more stable training and sometimes better convergence, but what if your GPU simply can’t handle the memory requirements of your ideal batch size?
Enter gradient accumulation - a simple yet powerful technique that allows you to effectively increase your batch size without increasing memory usage. In this post, I’ll show you how to implement this technique in PyTorch and explain why it might be exactly what your training pipeline needs.
What is Gradient Accumulation?
Gradient accumulation is a technique where you:
- Process smaller mini-batches sequentially
- Accumulate (add up) their gradients
- Update your model weights only after processing several mini-batches
This simulates training on a larger batch size without the memory requirements of loading that entire batch at once. It’s particularly useful when:
- You’re training very large models
- Working with limited GPU resources
- Need the stability of larger batch sizes
Implementing Gradient Accumulation in PyTorch
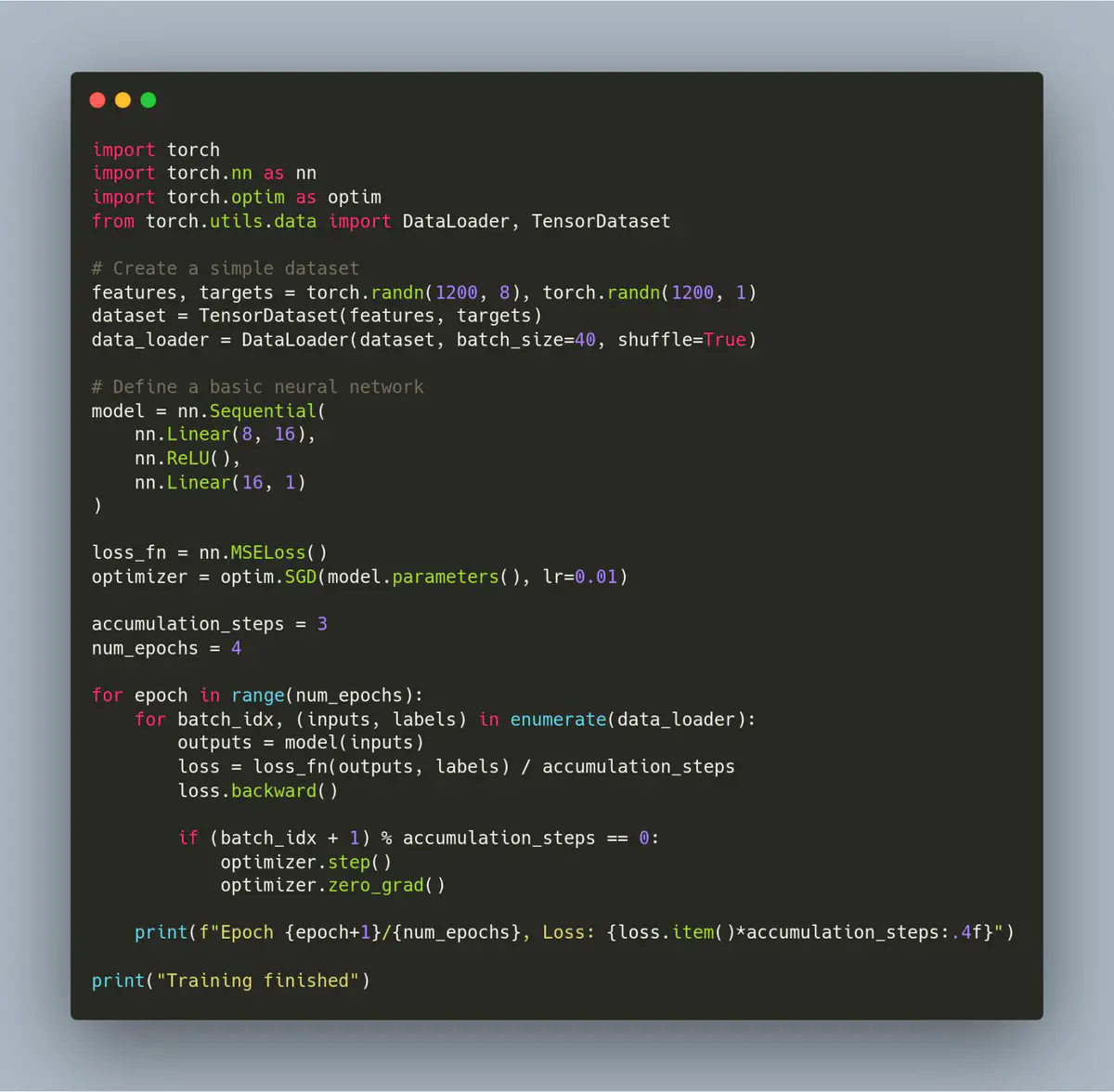
The implementation is surprisingly straightforward. Here’s a complete working example:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# Create a simple dataset
features, targets = torch.randn(1200, 8), torch.randn(1200, 1)
dataset = TensorDataset(features, targets)
data_loader = DataLoader(dataset, batch_size=40, shuffle=True)
# Define a basic neural network
model = nn.Sequential(
nn.Linear(8, 16),
nn.ReLU(),
nn.Linear(16, 1)
)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
accumulation_steps = 3
num_epochs = 4
for epoch in range(num_epochs):
for batch_idx, (inputs, labels) in enumerate(data_loader):
outputs = model(inputs)
loss = loss_fn(outputs, labels) / accumulation_steps
loss.backward()
if (batch_idx + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
print(f"Epoch {epoch + 1}/{num_epochs}, Loss: {loss.item() * accumulation_steps:.4f}")
print("Training finished")
Let’s break down the key components:
1. Set your accumulation steps
accumulation_steps = 3
This defines how many mini-batches to process before updating model weights.
2. Adjust your loss calculation
loss = loss_fn(outputs, labels) / accumulation_steps
We divide the loss by the number of accumulation steps to ensure the gradients are properly scaled.
3. Accumulate gradients but delay the optimizer step
loss.backward()
Call backward() as usual, but don’t immediately call optimizer.step().
4. Update weights after accumulation
if (batch_idx + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
Only after processing accumulation_steps batches do we update the weights and zero the gradients.
Benefits of Gradient Accumulation
1. Train with “Virtually” Larger Batch Sizes
With an accumulation_steps of 3 and a batch_size of 40 (as in our example), you’re effectively training with a batch size of 120, but with the memory footprint of just 40 examples at once.
2. Improved Training Stability
Larger effective batch sizes often lead to more stable gradients and smoother loss curves, especially for complex models.
3. Better Hardware Utilization
This technique allows you to fully utilize limited GPU resources while still benefiting from large-batch training dynamics.
Practical Considerations
When implementing gradient accumulation, keep these points in mind:
- Batch Normalization: If your model uses batch normalization layers, be aware that statistics are calculated per mini-batch, not across the accumulated batches. For some applications, this might affect performance.
- Learning Rate Scaling: With larger effective batch sizes, you might need to adjust your learning rate. A common heuristic is to scale the learning rate linearly with the effective batch size.
- Mixed Precision Training: Gradient accumulation works well with mixed precision training, giving you even more memory efficiency.
Conclusion
Gradient accumulation is one of those techniques that should be in every deep learning practitioner’s toolkit. It’s easy to implement, has almost no downside, and can dramatically improve your ability to train large models on limited hardware.
Give the provided code example a try in your next PyTorch project - you might be surprised at how much it improves your training process!
Happy training! 🚀
Further Resources
Mahyar Osanlouy
Scientist | Engineer
My research interests include machine learning and computational neuroscience.